mirror of
https://github.com/Rucknium/misc-research.git
synced 2025-04-04 21:07:28 +00:00
Black Marble Flood: Add DM decomp and p2p tx log analysis
This commit is contained in:
parent
7823fc72c3
commit
3dc973649a
10 changed files with 1295 additions and 23 deletions
Monero-Black-Marble-Flood
|
|
@ -0,0 +1,575 @@
|
|||
|
||||
|
||||
### INSTRUCTIONS
|
||||
# Run the R script below (Need more than 100GB of RAM)
|
||||
# Install Rust
|
||||
# Clone https://github.com/Rucknium/cryptonote-analysis
|
||||
# Then
|
||||
# cd cryptonote-analysis
|
||||
# cargo build --release
|
||||
# cd scripts/monero
|
||||
# g++ -O2 create_csparse_edges.cpp
|
||||
# ./a.out 3114046
|
||||
# # 3114046 should be same as current.height from R script
|
||||
# cargo run --release --bin dmdec csparse-edges-3114046.txt rings-before-dm-3114046.txt rings-after-dm-3114046.txt blocksizes-3114046.txt fine-decomp-3114046.txt
|
||||
# The output will say how many "ring size 1" rings exist after the DM decomposition
|
||||
|
||||
|
||||
|
||||
|
||||
# Need these packages:
|
||||
# install.packages("data.table")
|
||||
# install.packages("igraph")
|
||||
# install.packages("RCurl")
|
||||
# install.packages("RJSONIO")
|
||||
# install.packages("parallelly")
|
||||
# install.packages("future")
|
||||
# install.packages("future.apply")
|
||||
|
||||
|
||||
library(data.table)
|
||||
|
||||
|
||||
dm.decompsition.dir <- ""
|
||||
# Should be the parent directory, followed by cryptonote-analysis/scripts/monero/
|
||||
# Must have trailing "/"
|
||||
|
||||
|
||||
current.height <- 3114046 # 2024-03-27 06:30:37 UTC
|
||||
# Same as end.spam.height
|
||||
|
||||
edgelist.output.file <- paste0(dm.decompsition.dir, "edges-", current.height, ".txt")
|
||||
|
||||
start.height <- 1220516 # First RingCT outputs
|
||||
|
||||
url.rpc <- "http://127.0.0.1:18081"
|
||||
# Set the IP address and port of your node. Should usually be "http://127.0.0.1:18081"
|
||||
|
||||
|
||||
stopifnot(!is.na(current.height))
|
||||
|
||||
block.heights <- start.height:current.height
|
||||
|
||||
|
||||
|
||||
|
||||
# Modified from TownforgeR::tf_rpc_curl function
|
||||
xmr.rpc <- function(
|
||||
url.rpc = "http://127.0.0.1:18081/json_rpc",
|
||||
method = "",
|
||||
params = list(),
|
||||
userpwd = "",
|
||||
num.as.string = FALSE,
|
||||
nonce.as.string = FALSE,
|
||||
keep.trying.rpc = FALSE,
|
||||
curl = RCurl::getCurlHandle(),
|
||||
...
|
||||
){
|
||||
|
||||
json.ret <- RJSONIO::toJSON(
|
||||
list(
|
||||
jsonrpc = "2.0",
|
||||
id = "0",
|
||||
method = method,
|
||||
params = params
|
||||
), digits = 50
|
||||
)
|
||||
|
||||
rcp.ret <- tryCatch(RCurl::postForm(url.rpc,
|
||||
.opts = list(
|
||||
userpwd = userpwd,
|
||||
postfields = json.ret,
|
||||
httpheader = c('Content-Type' = 'application/json', Accept = 'application/json')
|
||||
# https://stackoverflow.com/questions/19267261/timeout-while-reading-csv-file-from-url-in-r
|
||||
),
|
||||
curl = curl
|
||||
), error = function(e) {NULL})
|
||||
|
||||
if (keep.trying.rpc && length(rcp.ret) == 0) {
|
||||
while (length(rcp.ret) == 0) {
|
||||
rcp.ret <- tryCatch(RCurl::postForm(url.rpc,
|
||||
.opts = list(
|
||||
userpwd = userpwd,
|
||||
postfields = json.ret,
|
||||
httpheader = c('Content-Type' = 'application/json', Accept = 'application/json')
|
||||
# https://stackoverflow.com/questions/19267261/timeout-while-reading-csv-file-from-url-in-r
|
||||
),
|
||||
curl = curl
|
||||
), error = function(e) {NULL})
|
||||
}
|
||||
}
|
||||
|
||||
if (is.null(rcp.ret)) {
|
||||
stop("Cannot connect to monerod. Is monerod running?")
|
||||
}
|
||||
|
||||
if (num.as.string) {
|
||||
rcp.ret <- gsub("(: )([-0123456789.]+)([,\n\r])", "\\1\"\\2\"\\3", rcp.ret )
|
||||
}
|
||||
|
||||
if (nonce.as.string & ! num.as.string) {
|
||||
rcp.ret <- gsub("(\"nonce\": )([-0123456789.]+)([,\n\r])", "\\1\"\\2\"\\3", rcp.ret )
|
||||
}
|
||||
|
||||
RJSONIO::fromJSON(rcp.ret, asText = TRUE) # , simplify = FALSE
|
||||
}
|
||||
|
||||
|
||||
|
||||
system.time({
|
||||
|
||||
n.workers <- min(floor(parallelly::availableCores()/2), 32L)
|
||||
|
||||
future::plan(future::multisession(workers = n.workers))
|
||||
options(future.globals.maxSize= 8000*1024^2)
|
||||
|
||||
set.seed(314)
|
||||
|
||||
# Randomize block heights to make processing time more uniform between parallel processes
|
||||
block.heights <- split(block.heights, sample(cut(block.heights, n.workers)))
|
||||
# First randomly put heights into list elements (split() will sort them ascendingly in each list element)
|
||||
block.heights <- lapply(block.heights, sample)
|
||||
# Then order the heights randomly within each list element
|
||||
block.heights <- unname(block.heights)
|
||||
|
||||
returned <- future.apply::future_lapply(block.heights, function(block.heights) {
|
||||
|
||||
handle <- RCurl::getCurlHandle()
|
||||
|
||||
return.data <- vector("list", length(block.heights))
|
||||
|
||||
for (height.iter in seq_along(block.heights)) {
|
||||
|
||||
height <- block.heights[height.iter]
|
||||
|
||||
block.data <- xmr.rpc(url.rpc = paste0(url.rpc, "/json_rpc"),
|
||||
method = "get_block",
|
||||
params = list(height = height ),
|
||||
keep.trying.rpc = TRUE,
|
||||
curl = handle)$result
|
||||
|
||||
txs.to.collect <- c(block.data$miner_tx_hash, block.data$tx_hashes)
|
||||
|
||||
rcp.ret <- tryCatch(RCurl::postForm(paste0(url.rpc, "/get_transactions"),
|
||||
.opts = list(
|
||||
postfields = paste0('{"txs_hashes":["', paste0(txs.to.collect, collapse = '","'), '"],"decode_as_json":true}'),
|
||||
httpheader = c('Content-Type' = 'application/json', Accept = 'application/json')
|
||||
),
|
||||
curl = handle
|
||||
), error = function(e) {NULL})
|
||||
|
||||
if (length(rcp.ret) == 0) {
|
||||
while (length(rcp.ret) == 0) {
|
||||
rcp.ret <- tryCatch(RCurl::postForm(paste0(url.rpc, "/get_transactions"),
|
||||
.opts = list(
|
||||
postfields = paste0('{"txs_hashes":["', paste0(txs.to.collect, collapse = '","'), '"],"decode_as_json":true}'),
|
||||
httpheader = c('Content-Type' = 'application/json', Accept = 'application/json')
|
||||
),
|
||||
curl = handle
|
||||
), error = function(e) {NULL})
|
||||
}
|
||||
}
|
||||
|
||||
rcp.ret <- RJSONIO::fromJSON(rcp.ret, asText = TRUE)
|
||||
|
||||
output.index.collected <- vector("list", length(txs.to.collect))
|
||||
rings.collected <- vector("list", length(txs.to.collect) - 1)
|
||||
|
||||
for (i in seq_along(txs.to.collect)) {
|
||||
|
||||
tx.json <- tryCatch(
|
||||
RJSONIO::fromJSON(rcp.ret$txs[[i]]$as_json, asText = TRUE),
|
||||
error = function(e) {NULL} )
|
||||
|
||||
if (is.null(tx.json)) {
|
||||
# stop()
|
||||
cat(paste0("tx: ", i, " block: ", height, "\n"), file = "~/RingCT-problems.txt", append = TRUE)
|
||||
next
|
||||
}
|
||||
|
||||
output.amounts <- sapply(tx.json$vout, FUN = function(x) {x$amount})
|
||||
|
||||
tx_size_bytes <- ifelse(i == 1,
|
||||
nchar(rcp.ret$txs[[i]]$pruned_as_hex) / 2,
|
||||
nchar(rcp.ret$txs[[i]]$as_hex) / 2)
|
||||
# Coinbase has special structure
|
||||
# Reference:
|
||||
# https://libera.monerologs.net/monero-dev/20221231
|
||||
# https://github.com/monero-project/monero/pull/8691
|
||||
# https://github.com/monero-project/monero/issues/8311
|
||||
|
||||
calc.tx.weight.clawback <- function(p) {
|
||||
pow.of.two <- 2^(1:4)
|
||||
pow.of.two.index <- findInterval(p, pow.of.two, left.open = TRUE) + 1
|
||||
num_dummy_outs <- pow.of.two[pow.of.two.index] - p
|
||||
transaction_clawback <- 0.8 * ( (23 * (p + num_dummy_outs)/2) * 32 - (2 * ceiling(log2(64 * p)) + 9) * 32 )
|
||||
# Equation from page 63 of Zero to Monero 2.0
|
||||
transaction_clawback
|
||||
}
|
||||
|
||||
if (length(tx.json$vout) == 2 && i > 1) {
|
||||
# i > 1 means not the first tx, which is the coinbase tx
|
||||
tx_weight_bytes <- tx_size_bytes
|
||||
} else {
|
||||
tx_weight_bytes <- tx_size_bytes + calc.tx.weight.clawback(length(tx.json$vout))
|
||||
}
|
||||
|
||||
|
||||
tx_fee <- ifelse(i == 1 || is.null(tx.json$rct_signatures), NA, tx.json$rct_signatures$txnFee)
|
||||
# missing non-RingCT tx fee
|
||||
|
||||
is.mordinal <-
|
||||
height >= 2838965 &&
|
||||
length(tx.json$vout) == 2 &&
|
||||
i > 1 && # not the first tx, which is the coinbase tx
|
||||
length(tx.json$extra) > 44 &&
|
||||
tx.json$extra[45] == 16
|
||||
# With "&&", evaluates each expression sequentially until it is false (if ever). Then stops.
|
||||
# If all are TRUE, then returns true.
|
||||
|
||||
is.mordinal.transfer <-
|
||||
height >= 2838965 &&
|
||||
length(tx.json$vout) == 2 &&
|
||||
i > 1 && # not the first tx, which is the coinbase tx
|
||||
length(tx.json$extra) > 44 &&
|
||||
tx.json$extra[45] == 17
|
||||
|
||||
output.index.collected[[i]] <- data.table(
|
||||
block_height = height,
|
||||
block_timestamp = block.data$block_header$timestamp,
|
||||
block_size = block.data$block_size,
|
||||
block_reward = block.data$reward,
|
||||
tx_num = i,
|
||||
tx_hash = txs.to.collect[i],
|
||||
tx_version = tx.json$version,
|
||||
tx_fee = tx_fee,
|
||||
tx_size_bytes = tx_size_bytes,
|
||||
tx_weight_bytes = tx_weight_bytes,
|
||||
number_of_inputs = length(tx.json$vin),
|
||||
number_of_outputs = length(tx.json$vout),
|
||||
output_num = seq_along(rcp.ret$txs[[i]]$output_indices),
|
||||
output_index = rcp.ret$txs[[i]]$output_indices,
|
||||
output_amount = output.amounts,
|
||||
output_unlock_time = tx.json$unlock_time,
|
||||
is_mordinal = is.mordinal,
|
||||
is_mordinal_transfer = is.mordinal.transfer)
|
||||
|
||||
|
||||
if (i == 1L) { next }
|
||||
# Skip first tx since it is the coinbase and has no inputs
|
||||
|
||||
tx_hash <- txs.to.collect[i]
|
||||
|
||||
rings <- vector("list", length(tx.json$vin))
|
||||
|
||||
for (j in seq_along(tx.json$vin)) {
|
||||
rings[[j]] <- data.table(
|
||||
tx_hash = tx_hash,
|
||||
input_num = j,
|
||||
input_amount = tx.json$vin[[j]]$key$amount,
|
||||
key_offset_num = seq_along(tx.json$vin[[j]]$key$key_offsets),
|
||||
key_offsets = tx.json$vin[[j]]$key$key_offsets
|
||||
)
|
||||
}
|
||||
|
||||
rings.collected[[i-1]] <- rbindlist(rings)
|
||||
|
||||
}
|
||||
|
||||
output.index.collected <- data.table::rbindlist(output.index.collected)
|
||||
rings.collected <- rbindlist(rings.collected)
|
||||
|
||||
return.data[[height.iter]] <- list(
|
||||
output.index.collected = output.index.collected,
|
||||
rings.collected = rings.collected)
|
||||
|
||||
}
|
||||
|
||||
return.data
|
||||
|
||||
} )
|
||||
})
|
||||
|
||||
future::plan(future::sequential)
|
||||
# Shut down workers to free RAM
|
||||
|
||||
|
||||
returned.temp <- vector("list", length(returned))
|
||||
|
||||
for (i in seq_along(returned)) {
|
||||
returned.temp[[i]] <- list(
|
||||
output.index.collected = rbindlist(lapply(returned[[i]],
|
||||
FUN = function(y) { y$output.index.collected })),
|
||||
rings.collected = rbindlist(lapply(returned[[i]],
|
||||
FUN = function(y) { y$rings.collected }))
|
||||
)
|
||||
}
|
||||
|
||||
returned.temp <- list(
|
||||
output.index.collected = rbindlist(lapply(returned.temp,
|
||||
FUN = function(y) { y$output.index.collected })),
|
||||
rings.collected = rbindlist(lapply(returned.temp,
|
||||
FUN = function(y) { y$rings.collected }))
|
||||
)
|
||||
|
||||
|
||||
|
||||
output.index <- returned.temp$output.index.collected
|
||||
returned.temp$output.index.collected <- NULL
|
||||
rings <- returned.temp$rings.collected
|
||||
rm(returned.temp)
|
||||
|
||||
setorder(rings, tx_hash, input_num, key_offset_num)
|
||||
|
||||
rings[, output_index := cumsum(key_offsets), by = c("tx_hash", "input_num")]
|
||||
|
||||
rings <- merge(rings, unique(output.index[, .(tx_hash, block_height, block_timestamp, tx_fee, tx_size_bytes)]), by = "tx_hash")
|
||||
|
||||
setnames(rings, c("block_height", "block_timestamp", "tx_fee", "tx_size_bytes"),
|
||||
c("block_height_ring", "block_timestamp_ring", "tx_fee_ring", "tx_size_bytes_ring"))
|
||||
|
||||
output.index[, output_amount_for_index := ifelse(tx_num == 1, 0, output_amount)]
|
||||
|
||||
output.index <- output.index[ !(tx_num == 1 & tx_version == 1), ]
|
||||
# Remove coinbase outputs that are ineligible for use in a RingCT ring
|
||||
# See https://libera.monerologs.net/monero-dev/20230323#c224570
|
||||
|
||||
|
||||
|
||||
xmr.rings <- merge(rings, output.index[, .(block_height, block_timestamp, tx_num, output_num,
|
||||
output_index, output_amount, output_amount_for_index, output_unlock_time, number_of_inputs,
|
||||
number_of_outputs, is_mordinal, is_mordinal_transfer, tx_fee, tx_size_bytes)],
|
||||
# only dont need tx_hash column from output.index
|
||||
by.x = c("input_amount", "output_index"),
|
||||
by.y = c("output_amount_for_index", "output_index")) #, all = TRUE)
|
||||
|
||||
|
||||
xmr.rings <- xmr.rings[input_amount == 0, ]
|
||||
# Remove non-RingCT rings
|
||||
|
||||
xmr.rings[, num_times_referenced := .N, by = "output_index"]
|
||||
|
||||
output.index.date <- unique(output.index[, .(block_timestamp = block_timestamp)])
|
||||
|
||||
output.index.date[, block_date := as.Date(as.POSIXct(block_timestamp, origin = "1970-01-01"))]
|
||||
|
||||
output.index <- merge(output.index, output.index.date)
|
||||
# speed improvement by splitting and then merging
|
||||
|
||||
gc()
|
||||
|
||||
|
||||
|
||||
# End ring gathering
|
||||
|
||||
# Start spam-era analysis
|
||||
|
||||
|
||||
|
||||
start.spam.height <- 3097764 # 2024-03-04 15:21:24
|
||||
start.spam.date <- as.Date("2024-03-04")
|
||||
|
||||
|
||||
end.spam.height <- 3114046 # 2024-03-27 06:30:37 UTC
|
||||
end.spam.date <- as.Date("2024-03-27")
|
||||
|
||||
|
||||
|
||||
|
||||
output.index[, block_date.week.day := weekdays(block_date)]
|
||||
|
||||
|
||||
spam.types <- list(list(
|
||||
fingerprint.text = "1in/2out 20 nanoneros/byte",
|
||||
fingerprint.crieria = substitute(
|
||||
floor((tx_fee/tx_size_bytes)/1000) %between% c(18, 22) &
|
||||
number_of_inputs == 1 &
|
||||
number_of_outputs == 2)),
|
||||
list(
|
||||
fingerprint.text = "1in/2out 20 or 320 nanoneros/byte",
|
||||
fingerprint.crieria = substitute(
|
||||
floor((tx_fee/tx_size_bytes)/1000) %between% c(315, 325) &
|
||||
number_of_inputs == 1 &
|
||||
number_of_outputs == 2)))
|
||||
|
||||
|
||||
spam.results <- list()
|
||||
|
||||
for (spam.type in seq_along(spam.types)) {
|
||||
|
||||
spam.fingerprint.all <- list()
|
||||
spam.fingerprint.tx.all <- list()
|
||||
|
||||
for (spam.type.sub in 1:spam.type) {
|
||||
|
||||
pre.spam.level.week.day <- output.index[
|
||||
# block_height < start.spam.height &
|
||||
block_date < start.spam.date &
|
||||
tx_num != 1 &
|
||||
eval(spam.types[[spam.type.sub]]$fingerprint.crieria),
|
||||
.(txs.rm.from.spam.set = round(uniqueN(tx_hash)/4)),
|
||||
# NOTE: /4 assumes number of pre-spam weeks in data is 4.
|
||||
by = "block_date.week.day"]
|
||||
|
||||
spam.fingerprint <- output.index[
|
||||
block_height %between% c(start.spam.height, end.spam.height) &
|
||||
tx_num != 1 &
|
||||
eval(spam.types[[spam.type.sub]]$fingerprint.crieria), ]
|
||||
|
||||
spam.fingerprint[, fingerprint := spam.types[[spam.type.sub]]$fingerprint.text]
|
||||
|
||||
spam.fingerprint.tx <- spam.fingerprint[!duplicated(tx_hash), ]
|
||||
|
||||
spam.fingerprint.tx <- merge(spam.fingerprint.tx,
|
||||
pre.spam.level.week.day[, .(block_date.week.day, txs.rm.from.spam.set)], by = "block_date.week.day")
|
||||
|
||||
set.seed(314)
|
||||
|
||||
|
||||
tx_hash.to.rm <- spam.fingerprint.tx[, .(tx_hash.to.rm = sample(tx_hash,
|
||||
min(c(unique(txs.rm.from.spam.set), length(tx_hash))), replace = FALSE)), by = "block_date"]
|
||||
spam.fingerprint.tx[, txs.rm.from.spam.set := NULL]
|
||||
spam.fingerprint.tx <- spam.fingerprint.tx[ ! tx_hash %chin% tx_hash.to.rm$tx_hash.to.rm, ]
|
||||
|
||||
spam.fingerprint.all[[spam.type.sub]] <- spam.fingerprint
|
||||
spam.fingerprint.tx.all[[spam.type.sub]] <- spam.fingerprint.tx
|
||||
|
||||
}
|
||||
|
||||
spam.fingerprint <- rbindlist(spam.fingerprint.all)
|
||||
spam.fingerprint.tx <- rbindlist(spam.fingerprint.tx.all)
|
||||
|
||||
non.spam.fingerprint <- output.index[ tx_num != 1 &
|
||||
(
|
||||
(! block_height %between% c(start.spam.height, end.spam.height)) |
|
||||
(block_height %between% c(start.spam.height, end.spam.height) &
|
||||
! (tx_hash %chin% spam.fingerprint.tx$tx_hash))
|
||||
), ]
|
||||
|
||||
non.spam.fingerprint.tx <- non.spam.fingerprint[!duplicated(tx_hash), ]
|
||||
|
||||
spam.results[[spam.type]] <- list(
|
||||
spam.fingerprint = spam.fingerprint, spam.fingerprint.tx = spam.fingerprint.tx,
|
||||
non.spam.fingerprint = non.spam.fingerprint, non.spam.fingerprint.tx = non.spam.fingerprint.tx
|
||||
)
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
# End spam analysis
|
||||
|
||||
# Start edgelist creation
|
||||
|
||||
|
||||
|
||||
xmr.rings[, c("is_mordinal", "is_mordinal_transfer", "tx_fee",
|
||||
"tx_size_bytes", "output_unlock_time", "tx_fee_ring", "tx_size_bytes_ring") := NULL]
|
||||
|
||||
gc()
|
||||
|
||||
set.seed(314)
|
||||
|
||||
xmr.rings.trimmed <- xmr.rings[
|
||||
block_height_ring >= start.spam.height,
|
||||
.(output_index, real.spend = seq_len(.N) == sample(.N, 1)),
|
||||
by = c("tx_hash", "input_num")
|
||||
]
|
||||
|
||||
|
||||
xmr.rings.trimmed <- xmr.rings.trimmed[
|
||||
(real.spend | ! output_index %in% spam.results[[2]]$spam.fingerprint$output_index) &
|
||||
(! tx_hash %in% spam.results[[2]]$spam.fingerprint.tx$tx_hash),
|
||||
.(output_index, tx_hash.input_num = paste0(tx_hash, "-", input_num))
|
||||
]
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
gc()
|
||||
|
||||
# xmr.rings has:
|
||||
# ringmember/input --> tx hash relation (output_index --> tx_hash)
|
||||
|
||||
# output.index has:
|
||||
# tx hash --> output relation (tx_hash --> output_index)
|
||||
|
||||
all.factor.levels <- c(unique(formatC(xmr.rings.trimmed$output_index, format = "d")),
|
||||
unique(xmr.rings.trimmed$tx_hash.input_num))
|
||||
# Must use formatC() so that the output_index integers are
|
||||
# converted to character correctly.
|
||||
|
||||
|
||||
edgelist <- unname(as.matrix(xmr.rings.trimmed[,
|
||||
.(formatC(output_index, format = "d"), tx_hash.input_num)]))
|
||||
|
||||
|
||||
gc()
|
||||
|
||||
edgelist <- structure(factor(edgelist, levels = all.factor.levels),
|
||||
dim = dim(edgelist), class = c('matrix', 'factor'))
|
||||
|
||||
rm(all.factor.levels)
|
||||
|
||||
class(edgelist) <- "matrix"
|
||||
attr(edgelist, "levels") <- NULL
|
||||
|
||||
stopifnot( ! any(is.na(c(edgelist))))
|
||||
|
||||
stopifnot(typeof(edgelist) == "integer")
|
||||
|
||||
gc()
|
||||
|
||||
table(duplicated(edgelist))
|
||||
|
||||
stopifnot( ! any(duplicated(edgelist)))
|
||||
|
||||
igraph.graph <- igraph::graph_from_edgelist(edgelist, directed = TRUE)
|
||||
|
||||
igraph.is.bipartite <- igraph::bipartite_mapping(igraph.graph)
|
||||
|
||||
str(igraph.is.bipartite)
|
||||
|
||||
stopifnot(igraph.is.bipartite$res)
|
||||
|
||||
rm(igraph.graph, igraph.is.bipartite)
|
||||
|
||||
edgelist <- edgelist[, c(2, 1)]
|
||||
|
||||
# colnames(edgelist) <- c("keyimage_id", "output_id")
|
||||
|
||||
data.table::fwrite(edgelist, file = edgelist.output.file,
|
||||
quote = FALSE, sep = " ", col.names = FALSE)
|
||||
|
||||
|
||||
# Then run the DM decomposition instructions
|
||||
|
||||
# This is the data to compare to:
|
||||
|
||||
effective.rings.before.DM <- xmr.rings.trimmed[, .(temp = .N), by = "tx_hash.input_num"][, table(temp)]
|
||||
|
||||
effective.rings.before.DM
|
||||
|
||||
100 * prop.table(effective.rings.before.DM)
|
||||
|
||||
# Then take the number from the displayed output:
|
||||
# "Singletons (traceable keyimages): XXXXX"
|
||||
|
||||
# And plug it in here:
|
||||
|
||||
DM.decomp.singletons <- NA
|
||||
|
||||
100 * DM.decomp.singletons / sum(effective.rings.before.DM)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
396
Monero-Black-Marble-Flood/code/p2p-log-analysis.R
Normal file
396
Monero-Black-Marble-Flood/code/p2p-log-analysis.R
Normal file
|
|
@ -0,0 +1,396 @@
|
|||
|
||||
# Turn on the p2p transaction receipt logging with `set_log net.p2p.msg:INFO`
|
||||
# in monerod
|
||||
|
||||
# First, prepare the log files for analysis
|
||||
# Uncomment these lines and run them:
|
||||
# install.packages("remotes")
|
||||
# remotes::install_github("Rucknium/xmrpeers")
|
||||
# And install hese if not already installed:
|
||||
# install.packages("data.table")
|
||||
# install.packages("ggplot2")
|
||||
# install.packages("gt")
|
||||
# install.packages("quantreg")
|
||||
# install.packages("circlize")
|
||||
# install.packages("skellam")
|
||||
|
||||
# If logs are in the standard location on the machine, do this to collect and compress the logs:
|
||||
xmrpeers::compress.log()
|
||||
|
||||
# Move the file to its final location (i.e. if the log files are in a machine
|
||||
# different from the one that will do the analysis, move them) and put it in
|
||||
# its own directory.
|
||||
|
||||
# Then the convert the log files into a data frame.
|
||||
# It can be useful to restart R between each file processed.
|
||||
|
||||
n.files <- NA
|
||||
log.file.directories <- paste0("", 1:n.files, "/")
|
||||
# Trailing slash here
|
||||
|
||||
for (i in log.file.directories) {
|
||||
output <- xmrpeers::get.p2p.log(paste0(i, "extracted-xmr-log"))
|
||||
saveRDS(output, paste0(i, "p2p-gossip.rds"))
|
||||
}
|
||||
|
||||
|
||||
# In a new R session, start loading the log data
|
||||
|
||||
library(data.table)
|
||||
|
||||
p2p.gossip <- list()
|
||||
|
||||
n.files <- NA
|
||||
log.file.directories <- paste0("", 1:n.files, "/")
|
||||
# Trailing slash here
|
||||
|
||||
for (i in log.file.directories) {
|
||||
p2p.gossip[[as.character(i)]] <- readRDS(paste0(i, "/p2p-gossip.rds"))
|
||||
}
|
||||
|
||||
p2p.gossip <- data.table::rbindlist(p2p.gossip, idcol = "file")
|
||||
|
||||
setorder(p2p.gossip, file, gossip.msg.id, time.log)
|
||||
|
||||
p2p.gossip <- p2p.gossip[time.p2p %between% c(as.POSIXct("2024-04-14"), as.POSIXct("2024-05-24")), ]
|
||||
|
||||
# Load ping data
|
||||
|
||||
peer.pings <- list()
|
||||
|
||||
for (i in log.file.directories) {
|
||||
peer.pings[[as.character(i)]] <- read.csv(paste0(i, "monero_peer_pings.csv"),
|
||||
header = FALSE, stringsAsFactors = FALSE)
|
||||
names(peer.pings[[as.character(i)]]) <- c("ip", "port", "direction", "ping1", "ping2", "ping3", "ping4", "ping5")
|
||||
}
|
||||
|
||||
peer.pings <- data.table::rbindlist(peer.pings, idcol = "file")
|
||||
|
||||
stopifnot(sum(duplicated(peer.pings[, .(file, ip, port, direction)]) == 0))
|
||||
|
||||
peer.pings[, port := as.character(port)]
|
||||
|
||||
peer.pings$median.ping <- apply(
|
||||
peer.pings[, .(ping1, ping2, ping3, ping4, ping5)], 1, FUN = median, na.rm = TRUE)
|
||||
|
||||
|
||||
# ****************************
|
||||
# Number of unique IP addresses
|
||||
# ****************************
|
||||
|
||||
|
||||
p2p.gossip[, uniqueN(ip)]
|
||||
# ^ Number of unique IP addresses in the dataset
|
||||
|
||||
|
||||
# ****************************
|
||||
# Duration of peer connections
|
||||
# ****************************
|
||||
|
||||
hour.seq <- seq(as.POSIXct("2023-01-01"), as.POSIXct("2024-06-01"), by = "1 hour")
|
||||
|
||||
p2p.gossip[, hour := cut(time.p2p, hour.seq)]
|
||||
|
||||
p2p.gossip.hour <- p2p.gossip[, .(n.hours = uniqueN(hour)), by = c("file", "ip", "direction")]
|
||||
|
||||
summary(p2p.gossip.hour$n.hours)
|
||||
|
||||
p2p.gossip.hour[, as.list(summary(n.hours)), by = "direction"]
|
||||
|
||||
setorder(p2p.gossip, time.p2p)
|
||||
|
||||
diff.hour <- p2p.gossip[, .(diff.hour = diff(as.numeric(hour))), by = c("file", "ip", "direction")]
|
||||
|
||||
diff.hour.summary <- diff.hour[, .(diff.hour = 1 + sum(diff.hour > 1)), by = c("file", "ip", "direction")]
|
||||
diff.hour.summary[is.na(diff.hour), diff.hour := 1] # Because if there was a missing for diff(), then it only appeared once.
|
||||
|
||||
diff.hour.summary[, as.list(summary(diff.hour)), by = "direction"]
|
||||
# ^ Number of distinct intervals it appears in the data
|
||||
|
||||
|
||||
conn.period <- function(x) {
|
||||
# https://stats.stackexchange.com/questions/107515/grouping-sequential-values-in-r
|
||||
y <- sort(x)
|
||||
conn.period <- cumsum(c(1, abs(y[-length(y)] - y[-1]) > 1))
|
||||
conn.period[match(y, x)]
|
||||
}
|
||||
|
||||
|
||||
p2p.gossip[, conn.period := conn.period(as.integer(hour)), by = c("file", "ip", "direction")]
|
||||
|
||||
diff.time <- p2p.gossip[, .(diff.time = diff(range(as.numeric(time.p2p)))), by = c("file", "ip", "direction", "conn.period")]
|
||||
|
||||
files.for.duration <- c()
|
||||
|
||||
diff.time[file %in% files.for.duration, as.list(summary(as.numeric(diff.time)/ 60))]
|
||||
|
||||
diff.time[file %in% files.for.duration, as.list(summary(as.numeric(diff.time)/ 60)), by = "direction"]
|
||||
# ^ Median duration of connections
|
||||
|
||||
|
||||
diff.time[file %in% files.for.duration & direction == "OUT", 100 * prop.table(table(as.numeric(diff.time)/ 60 > 6*60))]
|
||||
# ^ Share of outgoing connections lasting longer than 6 hours
|
||||
|
||||
diff.time[file %in% files.for.duration & direction == "OUT", 100 * prop.table(table(as.numeric(diff.time)/ 60 > 24*60))]
|
||||
# ^ Share of outgoing connections lasting longer than 24 hours
|
||||
|
||||
diff.time[file %in% files.for.duration & direction == "INC", 100 * prop.table(table(as.numeric(diff.time)/ 60 > 6*60))]
|
||||
# ^ Share of incoming connections lasting longer than 6 hours
|
||||
|
||||
diff.time[file %in% files.for.duration & direction == "INC", 100 * prop.table(table(as.numeric(diff.time)/ 60 > 24*60))]
|
||||
# ^ Share of incoming connections lasting longer than 24 hours
|
||||
|
||||
|
||||
|
||||
library(ggplot2)
|
||||
|
||||
png("Monero-Black-Marble-Flood/pdf/images/p2p-connection-duration.png")
|
||||
|
||||
ggplot(diff.time[file %in% files.for.duration & as.numeric(diff.time)/ 60 <= 200, ],
|
||||
aes(as.numeric(diff.time)/ 60, color = direction)) +
|
||||
labs(title = "Kernel density estimate of peer connection duration", x = "Connection duration (minutes)") +
|
||||
geom_density(bw = 1) +
|
||||
theme(legend.position = "top", legend.text = element_text(size = 12), legend.title = element_text(size = 15),
|
||||
plot.title = element_text(size = 16),
|
||||
plot.subtitle = element_text(size = 15),
|
||||
axis.text = element_text(size = 15),
|
||||
axis.title.x = element_text(size = 15, margin = margin(t = 10)),
|
||||
axis.title.y = element_text(size = 15), strip.text = element_text(size = 15)) +
|
||||
guides(colour = guide_legend(nrow = 1, byrow = FALSE, override.aes = list(linewidth = 5)))
|
||||
|
||||
dev.off()
|
||||
|
||||
# ****************************
|
||||
# Transaction sent by peers multiple times
|
||||
# ****************************
|
||||
|
||||
same.tx.sent <- p2p.gossip[, .(n.same.tx.sent = .N), by = c("tx.hash", "file", "ip", "port", "direction")]
|
||||
|
||||
round(100 * prop.table(table(same.tx.sent$n.same.tx.sent)), 2)
|
||||
# ^ Number of times each tx was received from the same peer
|
||||
|
||||
setorder(p2p.gossip, time.p2p)
|
||||
|
||||
time.diff.same.tx.sent <- p2p.gossip[tx.hash %chin% same.tx.sent[n.same.tx.sent >= 2, tx.hash],
|
||||
.(time.diff = diff(time.p2p), n.times.sent = .N), by = c("tx.hash", "file", "ip", "port", "direction")]
|
||||
|
||||
summary(as.numeric(time.diff.same.tx.sent$time.diff))
|
||||
|
||||
|
||||
n.send.times.max <- 16
|
||||
|
||||
median.send.delta.data <- median.send.delta.data.n <- c()
|
||||
|
||||
for (i in 1:n.send.times.max) {
|
||||
median.send.delta <- time.diff.same.tx.sent[n.times.sent >= (i + 1),
|
||||
.(temp = as.numeric(time.diff)[i]), by = "tx.hash"][, median(temp)]
|
||||
median.send.delta.data <- c(median.send.delta.data, median.send.delta)
|
||||
median.send.delta.data.n <- c(median.send.delta.data.n, sum(time.diff.same.tx.sent$n.times.sent >= (i + 1)))
|
||||
}
|
||||
|
||||
library(gt)
|
||||
|
||||
table.title <- "Time between duplicate transaction receipts"
|
||||
label <- "table-multiple-send-p2p"
|
||||
|
||||
multiple.send.tex <- gt(data.table(`Number of times received` = scales::label_ordinal()(1:n.send.times.max + 1),
|
||||
`Median minutes elapsed since previous time tx received` = round(median.send.delta.data, 2),
|
||||
`Number of txs (rounded to 10)` = prettyNum(round(median.send.delta.data.n, digits = -1), big.mark = ","))) |>
|
||||
tab_header(title = table.title) |>
|
||||
as_latex()
|
||||
|
||||
|
||||
latex.output <- multiple.send.tex |> as.character()
|
||||
|
||||
col.widths <- c(2.25, 3, 2.25)
|
||||
|
||||
latex.output <- gsub("begin[{]longtable[}][{][^\n]+",
|
||||
paste0("begin{longtable}{", paste0("Rp{", col.widths, "cm}", collapse = ""), "}"),
|
||||
latex.output)
|
||||
|
||||
latex.output <- gsub("caption*", "caption", latex.output, fixed = TRUE)
|
||||
# Removing the "*" means that the table is numbered in the final PDF output
|
||||
|
||||
latex.output <- gsub("\\end{longtable}",
|
||||
paste0("\\label{", label, "}\n\\end{longtable}"), latex.output, fixed = TRUE)
|
||||
|
||||
|
||||
cat(latex.output, file = "Monero-Black-Marble-Flood/pdf/tables/multiple-send-p2p.tex")
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
# ****************************
|
||||
# Clumping
|
||||
# ****************************
|
||||
|
||||
clumping <- p2p.gossip[, .(temp = .N), by = c("file", "gossip.msg.id")][, round(100 * prop.table(table(temp)), 2)]
|
||||
|
||||
clumping <- c(clumping) # Convert from table to vector
|
||||
clumping <- c(clumping[as.numeric(names(clumping)) <= 10], `> 10` = sum(clumping[as.numeric(names(clumping)) > 10]))
|
||||
|
||||
|
||||
table.title <- "Transactions clumping in gossip messages"
|
||||
label <- "table-tx-clumping-p2p"
|
||||
|
||||
|
||||
clumping.tex <- gt(data.table(`Number of txs in message` = names(clumping),
|
||||
`Share of messages (percentage)` = round(clumping, 2))) |>
|
||||
tab_header(title = table.title) |>
|
||||
cols_align(align = "right") |>
|
||||
as_latex()
|
||||
|
||||
latex.output <- clumping.tex |> as.character()
|
||||
|
||||
col.widths <- c(2.25, 3)
|
||||
|
||||
latex.output <- gsub("begin[{]longtable[}][{][^\n]+",
|
||||
paste0("begin{longtable}{", paste0("Rp{", col.widths, "cm}", collapse = ""), "}"),
|
||||
latex.output)
|
||||
|
||||
latex.output <- gsub("caption*", "caption", latex.output, fixed = TRUE)
|
||||
# Removing the "*" means that the table is numbered in the final PDF output
|
||||
|
||||
latex.output <- gsub("\\end{longtable}",
|
||||
paste0("\\label{", label, "}\n\\end{longtable}"), latex.output, fixed = TRUE)
|
||||
|
||||
|
||||
cat(latex.output, file = "Monero-Black-Marble-Flood/pdf/tables/tx-clumping-p2p.tex")
|
||||
|
||||
|
||||
|
||||
# ****************************
|
||||
# How does ping time affect time to receive tx?
|
||||
# ****************************
|
||||
|
||||
library(quantreg)
|
||||
|
||||
time.since.first.receipt.pings <- p2p.gossip[ file %in% unique(peer.pings$file), .(time.since.first.receipt = time.p2p - min(time.p2p),
|
||||
ip = ip, port = port, direction = direction), by = c("file", "tx.hash")]
|
||||
|
||||
|
||||
time.since.first.receipt.pings <- merge(time.since.first.receipt.pings, peer.pings)
|
||||
|
||||
|
||||
summary(lm(as.numeric(time.since.first.receipt)*1000 ~ I(median.ping/2),
|
||||
data = time.since.first.receipt.pings[time.since.first.receipt %between% c(0, 60),]))
|
||||
# *1000 is to convert to millisecond units. /2 is to make round-trip ping into single-leg ping
|
||||
#
|
||||
|
||||
summary(rq(as.numeric(time.since.first.receipt)*1000 ~ I(median.ping/2),
|
||||
tau = 0.5, data = time.since.first.receipt.pings, method = "fn"))
|
||||
#
|
||||
|
||||
|
||||
# ****************************
|
||||
# Tx arrival times when two logging nodes are connected to the same peer
|
||||
# ****************************
|
||||
|
||||
|
||||
unique.conn.hours <- unique(p2p.gossip[, .(file, ip, port, direction, hour)])
|
||||
our.nodes.connected <- unique.conn.hours[, .(n.our.nodes.connected = .N), by = c("ip", "port", "hour")]
|
||||
our.nodes.connected <- merge(our.nodes.connected[n.our.nodes.connected == 2, .(ip, hour)], unique.conn.hours)
|
||||
# A few have our.nodes.connected == 3, but it is very rare and harder to analyze, so skip
|
||||
our.nodes.connected <- merge(our.nodes.connected, p2p.gossip, by = c("ip", "hour", "file", "port"))
|
||||
|
||||
setorder(our.nodes.connected, file, time.p2p)
|
||||
# Set order by file so the "first" and "second" nodes are in consistent order.
|
||||
# Set next order priority by time.p2p so that the next step works properly
|
||||
|
||||
our.nodes.connected <- unique(our.nodes.connected, by = c("file", "ip", "port", "tx.hash"))
|
||||
# Sometimes a peer sends the same transaction more than once, so eliminate the later duplicate
|
||||
|
||||
our.nodes.connected <- our.nodes.connected[, .(tx.hash.time.diff = diff(time.p2p),
|
||||
gossip.msg.id.1 = gossip.msg.id[1], gossip.msg.id.2 = gossip.msg.id[2],
|
||||
file.1 = file[1], file.2 = file[2]), by = c("ip", "port", "hour", "tx.hash")]
|
||||
|
||||
|
||||
our.nodes.connected[, tx.hash.time.diff := as.numeric(tx.hash.time.diff)]
|
||||
|
||||
pair.in.time.sync <- c()
|
||||
|
||||
|
||||
|
||||
library(circlize)
|
||||
|
||||
# Circular density
|
||||
|
||||
|
||||
simul.connection.data <- our.nodes.connected[tx.hash.time.diff <= 60 &
|
||||
(file.1 %in% pair.in.time.sync & file.2 %in% pair.in.time.sync),
|
||||
tx.hash.time.diff]
|
||||
|
||||
circ.data <- ifelse(simul.connection.data >= 0, simul.connection.data %% 1,
|
||||
abs(simul.connection.data %% -1))
|
||||
# Compute modulo
|
||||
|
||||
circ.data <- c(circ.data - 1, circ.data, circ.data + 1)
|
||||
# This gives us a "circular" support so we do not have the
|
||||
# kernel density boundary issue
|
||||
|
||||
density.data <- density(circ.data, bw = 0.01, n = 512 * 3)
|
||||
|
||||
density.data$y <- density.data$y[density.data$x %between% c(-0.005, 1.005) ]
|
||||
density.data$x <- density.data$x[density.data$x %between% c(-0.005, 1.005) ]
|
||||
|
||||
|
||||
png("Monero-Black-Marble-Flood/pdf/images/one-second-period-tx-p2p-msg.png")
|
||||
|
||||
circos.par(start.degree = 90, gap.degree = 0, circle.margin = 0.15)
|
||||
|
||||
circos.initialize(sectors = rep("A", length(circ.data)), x = circ.data, xlim = c(0, 1))
|
||||
|
||||
circos.trackPlotRegion(ylim = c(0, max(density.data$y)), track.height = .9)
|
||||
|
||||
circos.trackLines(sectors = rep("A", length(density.data$x)), density.data$x, density.data$y,
|
||||
track.index = 1, area = TRUE, col = "#999999", border = "black" )
|
||||
|
||||
circos.xaxis(major.at = c(0, 0.25, 0.50, 0.75),
|
||||
labels = c(0, expression(frac(1, 4)), expression(1/2), expression(frac(3, 4))),
|
||||
labels.facing = "downward", labels.col = "darkred", labels.pos.adjust = FALSE)
|
||||
|
||||
axis.marks <- c(0.5, 1, 1.5)
|
||||
|
||||
circos.yaxis(at = axis.marks)
|
||||
|
||||
for (i in axis.marks) {
|
||||
circos.trackLines(sectors = rep("A", 2), c(0, 1), rep(i, 2), lty = 2,
|
||||
track.index = 1 )
|
||||
}
|
||||
|
||||
|
||||
|
||||
circos.clear()
|
||||
|
||||
title(main = "One-second cycle of time difference between same\ntx received from two different nodes")
|
||||
title(sub = "Fractional seconds")
|
||||
|
||||
dev.off()
|
||||
|
||||
|
||||
|
||||
# Histogram
|
||||
|
||||
n.subsecond.intervals <- 8
|
||||
hist.range <- c(-5 - (1/2)/n.subsecond.intervals, 5 + (1/2)/n.subsecond.intervals)
|
||||
|
||||
skellam.points <- n.subsecond.intervals * skellam::dskellam(-20:20, lambda1 = 20, lambda2 = 20)
|
||||
|
||||
png("Monero-Black-Marble-Flood/pdf/images/skellam-histogram-tx-p2p-msg.png")
|
||||
|
||||
hist(simul.connection.data[simul.connection.data %between% hist.range],
|
||||
breaks = seq(hist.range[1], hist.range[2], by = 1/n.subsecond.intervals), probability = TRUE,
|
||||
main = "Time difference between same tx received from two different nodes",
|
||||
xlab = "Time difference (seconds)")
|
||||
|
||||
points(-20:20/4, skellam.points, col = "red")
|
||||
segments(-20:20/4, 0, -20:20/4, skellam.points, col = "red")
|
||||
legend("topleft", legend = c("Histogram", "Theoretical Skellam\ndistribution"),
|
||||
fill = c("lightgray", NA), border = c("black", NA), pch = c(NA, 21),
|
||||
col = c(NA, "red"), bty = "n")
|
||||
|
||||
dev.off()
|
||||
|
||||
|
||||
|
||||
{kind=link}
Binary file not shown.
|
After 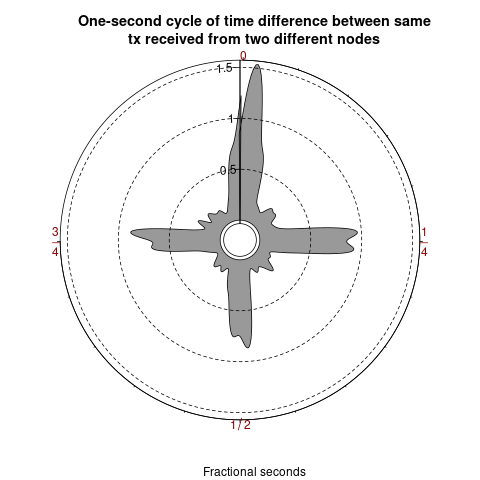
(image error) Size: 43 KiB |
BIN
Monero-Black-Marble-Flood/pdf/images/p2p-connection-duration.png
Normal file
BIN
Monero-Black-Marble-Flood/pdf/images/p2p-connection-duration.png
Normal file
{kind=link}
Binary file not shown.
|
After 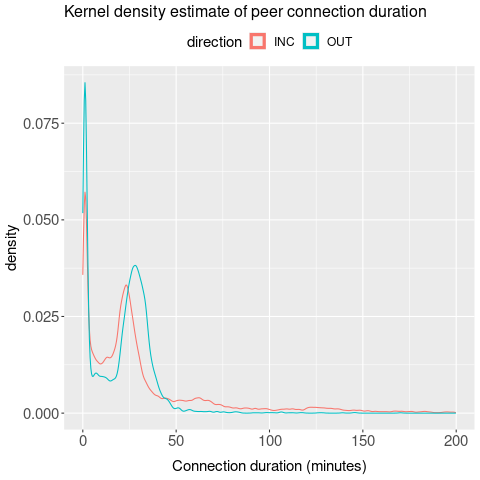
(image error) Size: 26 KiB |
{kind=link}
Binary file not shown.
|
After 
(image error) Size: 24 KiB |
|
|
@ -122,6 +122,30 @@ year = {2010}
|
|||
keywords = "Cryptography and Security (cs.CR),FOS: Computer and information sciences"
|
||||
}
|
||||
|
||||
|
||||
@inproceedings{Cao2020,
|
||||
title = "Exploring the Monero Peer-to-Peer Network",
|
||||
ISBN = "978-3-030-51280-4",
|
||||
year = "2020",
|
||||
URL = "https://link.springer.com/chapter/10.1007/978-3-030-51280-4_31",
|
||||
booktitle = "Financial Cryptography and Data Security",
|
||||
pages = "578--594",
|
||||
author = "Cao, Tong and Yu, Jiangshan and Decouchant, Jeremie and Luo, Xiapu and Verissimo, Paulo",
|
||||
editor = "Bonneau, Joseph and Heninger, Nadia",
|
||||
abstract = "As of September 2019, Monero is the most capitalized privacy-preserving cryptocurrency, and is ranked tenth among all cryptocurrencies. Monero's on-chain data privacy guarantees, i.e., how mixins are selected in each transaction, have been extensively studied. However, despite Monero's prominence, the network of peers running Monero clients has not been analyzed. Such analysis is of prime importance, since potential vulnerabilities in the peer-to-peer network may lead to attacks on the blockchain's safety (e.g., by isolating a set of nodes) and on users' privacy (e.g., tracing transactions flow in the network).",
|
||||
publisher = "Springer International Publishing"
|
||||
}
|
||||
|
||||
@article{Franzoni2022b,
|
||||
title = "SoK: Network-Level Attacks on the Bitcoin P2P Network",
|
||||
ISSN = "2169-3536",
|
||||
DOI = "10.1109/ACCESS.2022.3204387",
|
||||
volume = "10",
|
||||
year = "2022",
|
||||
URL = "https://ieeexplore.ieee.org/abstract/document/9877811",
|
||||
journal = "IEEE Access",
|
||||
pages = "94924--94962",
|
||||
author = "Franzoni, Federico and Daza, Vanesa",
|
||||
abstract = "Over the last decade, Bitcoin has revolutionized the global economic and technological landscape, inspiring a new generation of blockchain-based technologies. Its protocol is today among the most influential for cryptocurrencies and distributed networks. In particular, the P2P layer represents a reference point for all permissionless blockchains, which often implement its solutions in their network layer. Unfortunately, the Bitcoin network protocol lacks a strong security model, leaving it exposed to several threats. Attacks at this level can affect the reliability and trustworthiness of the consensus layer, mining the credibility of the whole system. It is therefore of utmost importance to properly understand and address the security of the Bitcoin P2P protocol. In this paper, we give a comprehensive and detailed overview of known network-level attacks in Bitcoin, as well as the countermeasures that have been implemented in the protocol. We propose a generic network adversary model, and propose an objective-based taxonomy of the attacks. Finally, we identify the core weaknesses of the protocol and study the relationship between different types of attack. We believe our contribution can help both new and experienced researchers have a broader and deeper understanding of the Bitcoin P2P network and its threats, and allow for a better modeling of its security properties."
|
||||
}
|
||||
|
||||
|
||||
|
|
|
|||
Binary file not shown.
|
|
@ -5,6 +5,7 @@
|
|||
|
||||
|
||||
\usepackage{float}
|
||||
\usepackage{wrapfig}
|
||||
|
||||
%Primary packages
|
||||
\usepackage{fancyvrb}
|
||||
|
|
@ -58,6 +59,14 @@
|
|||
\usepackage{multirow}
|
||||
\usepackage{stackrel}
|
||||
\usepackage{rotating}
|
||||
\usepackage{longtable}
|
||||
\usepackage{booktabs}
|
||||
|
||||
|
||||
|
||||
\newcolumntype{L}{>{\raggedright\arraybackslash}}
|
||||
\newcolumntype{R}{>{\raggedleft\arraybackslash}}
|
||||
\newcolumntype{C}{>{\centering\arraybackslash}}
|
||||
|
||||
|
||||
% https://tex.stackexchange.com/questions/151241/remove-metadata-of-pdf-generated-by-latex
|
||||
|
|
@ -87,9 +96,9 @@
|
|||
\begin{document}
|
||||
\title{March 2024 Suspected Black Marble Flooding Against Monero:
|
||||
Privacy, User Experience, and Countermeasures\\\vspace{.3cm}
|
||||
\large Draft v0.2\vspace{-.715cm}}
|
||||
\author{Rucknium\orcidlink{https://orcid.org/0000-0001-5999-8950} }
|
||||
\date{March 27, 2024}
|
||||
\large Draft v0.3\vspace{-.715cm}}
|
||||
\author{Rucknium\orcidlink{0000-0001-5999-8950} }
|
||||
\date{October 9, 2024}
|
||||
\maketitle
|
||||
\begin{abstract}
|
||||
On March 4, 2024, aggregate Monero transaction volume suddenly almost
|
||||
|
|
@ -471,12 +480,40 @@ This is a modest gain of attack effectiveness, but \cite{Chervinski2021}
|
|||
appears to be using a suboptimal chain reaction algorithm instead
|
||||
of the closed set attack.
|
||||
|
||||
The actual risk from chain reaction analysis in the suspected March
|
||||
2024 flooding is a gap in our knowledge. \cite{Vijayakumaran2023}
|
||||
provides an open source implementation of the DM decomposition in
|
||||
Rust and excellent documentation.\footnote{\url{https://github.com/avras/cryptonote-analysis}\\
|
||||
\url{https://www.respectedsir.com/cna}} A Monte Carlo simulation applying the DM decomposition to the March
|
||||
2024 black marble estimates should be written.
|
||||
I implemented a DM decomposition simulation, using the real data from
|
||||
the black marble era of transactions as the starting point. The set
|
||||
of transactions produced by the adversary is known only to the adversary,
|
||||
so a reasonable guess was required. First, transactions that fit the
|
||||
spamming criteria were randomly assigned to black marble status in
|
||||
a proportion equal to the spam volume. Second, each ring was randomly
|
||||
assigned a real spend so that rings in non-black marble transactions
|
||||
would not entirely disappear in the next step. Third, outputs in black
|
||||
marble transactions were removed from the rings of non-black-marble
|
||||
transactions, except when the ``real spend'' assigned in the previous
|
||||
step would be removed. Fourth, all black marble transactions were
|
||||
removed from the dataset. The transaction graph left after these deletions
|
||||
is not necessarily internally consistent (i.e. funds might not actually
|
||||
be able to flow between transactions), but the objective is to approximate
|
||||
a chain reaction attack. Fifth, I used a modified version of the DM
|
||||
decomposition developed by \cite{Vijayakumaran2023} to simulate a
|
||||
chain reaction attack.\footnote{\url{https://github.com/avras/cryptonote-analysis}\\
|
||||
\url{https://www.respectedsir.com/cna}}
|
||||
|
||||
After the black marble outputs were removed but before the DM decomposition
|
||||
was applied, 0.57 percent of rings in the simulated dataset had a
|
||||
single ring member left. The real spend could be deduced in these
|
||||
0.57 percent of rings. This simulated estimate is consistent with
|
||||
the results in Figure \ref{fig-share-ring-size-one} that uses the
|
||||
$f\left(0,n-1,\frac{\mathrm{E}\left[n_{e}\right]-1}{n-1}\right)$
|
||||
formula instead of a simulation. After the DM decomposition was applied
|
||||
to the simulated dataset, the share of rings whose real spend could
|
||||
be deterministically deduced increased to 0.82 percent. Therefore,
|
||||
the DM decomposition would increase the black-marble adversary's ability
|
||||
to deterministically deduce the real spend by 44 percent. My simulation
|
||||
results can be compared to the results of \cite{Chervinski2021} in
|
||||
a different parameter environment, which found a 22 percent increase
|
||||
from a chain reaction attack (the share of rings with effective ring
|
||||
size one increased from 11.9 to 14.5 percent).
|
||||
|
||||
\section{Countermeasures}
|
||||
|
||||
|
|
@ -635,7 +672,7 @@ to the network, transactions did not drop out of the mempool. They
|
|||
just took longer to confirm. There were only two transaction IDs in
|
||||
the mempool of one of the mempool archive nodes that did not confirm
|
||||
during the spam period. Both occurred on March 8 when the mempool
|
||||
was very congested. The the two ``disappearing transactions'' could
|
||||
was very congested. The two ``disappearing transactions'' could
|
||||
happen if someone submits a transactions to an overloaded public RPC
|
||||
node, the transactions does not propagate well, and then the user
|
||||
reconstructs the transactions with another node. The first transaction
|
||||
|
|
@ -672,18 +709,211 @@ the spam hypothesis.
|
|||
More can be done to generate evidence for or against the spam hypothesis.
|
||||
\cite{Krawiec-Thayer2021} analyzed the age of all ring members. Using
|
||||
the OSPEAD techniques, the distribution of the age of the real spends
|
||||
can be estimated.\footnote{\url{https://github.com/Rucknium/OSPEAD}}
|
||||
The Monero node network can be actively crawled to see if the spam
|
||||
transactions originate from one node. Dandelion++ can defeat attempts
|
||||
to discover the origin of most transaction because the signal of the
|
||||
real transaction is covered by the Dandelion++ noise. When the signal
|
||||
is huge like the spam, some statistical analysis could overcome the
|
||||
Dandelion++ protection. Investigatory nodes could use \texttt{set\_log
|
||||
net.p2p.msg:INFO} to view which neighboring nodes the suspected spam
|
||||
is coming from. Then the investigatory node could crawl the network
|
||||
in the direction of the highest incoming volume. The techniques of
|
||||
\cite{Sharma2022} are useful at extremely high transaction volumes,
|
||||
like in the spam case, and could be used.
|
||||
can be estimated.\footnote{\url{https://github.com/Rucknium/OSPEAD}}
|
||||
|
||||
Dandelion++ can defeat attempts to discover the origin of most transactions
|
||||
because the signal of the real transaction is covered by the Dandelion++
|
||||
noise. When the signal is huge like the spam, some statistical analysis
|
||||
could overcome the Dandelion++ protection. Node can use the \texttt{net.p2p.msg:INFO}
|
||||
log setting to record incoming fluff-phase transactions. From April
|
||||
14, 2024 to May 23, 2024, peer-to-peer log data was collected from
|
||||
about ten Monero nodes to try to establish evidence that the suspected
|
||||
black marble transactions originated from a single node.\footnote{Thanks to cyrix126, Nep Nep, and anonymous node operators for contributing
|
||||
log data.} Two factors have made this difficult. First, network topology information,
|
||||
i.e. which nodes are connected to each other, is not easily obtained.
|
||||
\cite{Cao2020} used the last\_seen timestamp in peer-to-peer communications
|
||||
to estimate the node topology, but the timestamp has been removed
|
||||
from Monero's node code.\footnote{\url{https://github.com/monero-project/monero/pull/5681} and \url{https://github.com/monero-project/monero/pull/5682}}
|
||||
Topology information would have allowed a ``node crawler'' to move
|
||||
through the network toward the likely source of the transaction spam.
|
||||
Second, log data collection started after the spam wave ended, and
|
||||
no new spam waves appeared. Therefore, the aim of the data analysis
|
||||
had to change. The following analysis uncovers facts about Monero's
|
||||
network and transaction propagation during normal operation that could
|
||||
provide a foundation for future research on the network's privacy
|
||||
and transaction propagation properties.
|
||||
|
||||
The number of unique IP addresses of peer nodes in the dataset is
|
||||
about 13,600. This may be a rough estimate of the total number of
|
||||
nodes on the network. Counting nodes this way can create both under-counts
|
||||
and over-counts because of nodes entering and leaving the network,
|
||||
nodes changing IP addresses, and multiple nodes behind the same IP
|
||||
address. In any case, the 13,600 figure is similar to a May 29, 2024
|
||||
count by \texttt{monero.fail} of about 12,000 nodes on the network.\footnote{https://web.archive.org/web/20240529014020/https://monero.fail/map}
|
||||
|
||||
The stability of the network topology is one of the factors that influences
|
||||
the effectiveness of Monero's Dandelion++ network privacy protocol.
|
||||
When nodes are connected to each other for a long time, it is easier
|
||||
for an adversary to get information about network topology and use
|
||||
it to try to discover the true node origin of a transaction (\cite{Sharma2022}).
|
||||
The rate of connection creation and destruction could also affect
|
||||
the vulnerability of the network to partitioning and eclipse attacks
|
||||
(\cite{Franzoni2022b}).
|
||||
|
||||
A node can have two basic type of connections: incoming and outgoing.
|
||||
A node's ``incoming'' connections are connections that the node's
|
||||
peer initiated. A node's ``outgoing'' connections are connections
|
||||
that the node initiated. By default, nodes that are behind a firewall
|
||||
or residential router usually do not accept incoming connections.
|
||||
The default maximum number of outgoing connections is 12. There is
|
||||
no limit on incoming connections by default, but usually nodes accepting
|
||||
incoming connections have between 50 and 100 incoming connections.
|
||||
|
||||
\begin{wrapfigure}{I}{0.45\columnwidth}%
|
||||
|
||||
\caption{Peer connection duration}
|
||||
|
||||
\label{fig-p2p-connection-duration}
|
||||
\begin{centering}
|
||||
\includegraphics[scale=0.5]{images/p2p-connection-duration}
|
||||
\par\end{centering}
|
||||
\end{wrapfigure}%
|
||||
\begin{wraptable}{O}{0.45\columnwidth}%
|
||||
\input{tables/multiple-send-p2p.tex}\end{wraptable}%
|
||||
|
||||
Based on the timestamps of transaction gossip messages from nodes
|
||||
that accept incoming connections, the median duration of incoming
|
||||
connections was 23 minutes. For outgoing connections, the median duration
|
||||
was 23.5 minutes. A small number of connections last for much longer.
|
||||
About 1.5 percent of incoming connections lasted longer than 6 hours.
|
||||
About 0.2 percent of incoming connections lasted longer than 24 hours.
|
||||
No outgoing connections lasted longer than six hours. This means that
|
||||
some peer nodes chose to keep connections alive for a long period
|
||||
of time. Node operators can manually set the \texttt{-{}-add-priority-node}
|
||||
or \texttt{-{}-add-exclusive-node} node startup option to maintain
|
||||
longer connections. Figure \ref{fig-p2p-connection-duration} is a
|
||||
kernel density estimate of the duration of incoming and outgoing connections.
|
||||
A small number of connections last for only a few minutes. A large
|
||||
number of connections end at about 25 minutes.
|
||||
|
||||
Monero's fluff-phase transaction propagation is a type of gossip protocol.
|
||||
In most gossip protocols, nodes send each unique message to each peer
|
||||
one time at most. Monero nodes will sent a transaction to the same
|
||||
peer multiple times if the transaction has not been confirmed by miners
|
||||
after a period of time. Arguably, this behavior makes transaction
|
||||
propagation more reliable, at the cost of higher bandwidth usage.
|
||||
Usually, transactions are confirmed immediately when the next block
|
||||
is mined, so transactions are not sent more than once. If the transaction
|
||||
pool is congested or if there is an unusually long delay until the
|
||||
next block is mined, transactions may be sent more than once. In the
|
||||
dataset, about 93 percent of transactions were received from the same
|
||||
peer only once. About 6 percent were received from the same peer twice.
|
||||
About 1 percent of transactions were received from the same peer more
|
||||
than twice.
|
||||
|
||||
Table \ref{table-multiple-send-p2p} shows the median time interval
|
||||
between receiving duplicate transaction from the same peer. Up to
|
||||
the seventh relay, the $i$th relay has a delay of $f(i)=5\cdot2^{i-2}$.
|
||||
After the seventh relay, the data suggests that some peers get stuck
|
||||
broadcasting transactions every two to four minutes.\footnote{boog900 stated that ``re-broadcasts happen after 5 mins then 10,
|
||||
then 15 increasing the wait by 5 mins each time upto {[}sic{]} 4 hours
|
||||
where it is capped''. The form of this additive delay is similar
|
||||
to the exponential delay that the empirical data suggests. https://libera.monerologs.net/monero-research-lab/20240828\#c418612}
|
||||
|
||||
A Monero node's fluff-phase gossip message can contain more than one
|
||||
transaction. Usually, when a stem-phase transaction converts into
|
||||
a fluff-phase transaction, it will be the only transaction in its
|
||||
gossip message. As transactions propagates through the network, they
|
||||
will tend to clump together into gossip messages with other transactions.
|
||||
The clumping occurs because nodes maintain a single fluff-phase delay
|
||||
timer for each connection. As soon as the ``first'' transaction
|
||||
is received from a peer, a Poisson-distributed random timer is set
|
||||
for each connection to a peer. If a node receives a ``second'',
|
||||
``third'', etc. transaction before a connection's timer expires,
|
||||
then those transaction are grouped with the first one in a single
|
||||
message that eventually is sent to the peer when the timer expires.
|
||||
Table \ref{table-tx-clumping-p2p} is shows the distribution of clumping.
|
||||
About 25 percent of gossip messages contained just one transaction.
|
||||
Another 25 percent contained two transactions. The remaining messages
|
||||
contained three or more transactions.
|
||||
|
||||
\begin{wraptable}{O}{0.35\columnwidth}%
|
||||
\input{tables/tx-clumping-p2p.tex}\end{wraptable}%
|
||||
|
||||
A subset of the nodes that collected the peer-to-peer log data also
|
||||
collected network latency data through ping requests to peer nodes.
|
||||
The data can be used to analyze how network latency affects transaction
|
||||
propagation. When it takes longer for a peer node to send a message
|
||||
to the data logging node, we expect that data logging node will receive
|
||||
transactions from high-latency nodes later, on average, than from
|
||||
low-latency nodes. I estimated an Ordinary Least Squares (OLS) regression
|
||||
model to evaluate this hypothesis. First, I computed the time interval
|
||||
between the first receipt of a transaction from any node and the time
|
||||
that each node sent the transaction: \texttt{time\_since\_first\_receipt}.
|
||||
Then, the round-trip ping time was divide by two to get the one-way
|
||||
network latency: \texttt{one\_way\_ping}. The regression equation
|
||||
was \texttt{time\_since\_first\_receipt = one\_way\_ping + error\_term}
|
||||
|
||||
The estimated coefficient on \texttt{one\_way\_ping} was 7.5 (standard
|
||||
error: 0.02). This is the expected direction of the association, but
|
||||
the magnitude seems high. The coefficient means that a one millisecond
|
||||
increase in ping time was associated with a 7.5 millisecond increase
|
||||
in the time to receive the transaction from the peer. If the effect
|
||||
of ping on transaction receipt delay only operated through the connection
|
||||
between the peer node and the logging node, we may expect an estimated
|
||||
coefficient value of one. There are at least two possible explanations
|
||||
for the high estimated coefficient. First, assume that the logging
|
||||
nodes were located in a geographic area with low average ping to peers.
|
||||
And assume that the high-ping peers were located in an area with high
|
||||
average ping to peers. Then, the high-ping nodes would have high delay
|
||||
in sending \textit{and} receiving transactions from the ``low-ping''
|
||||
cluster of nodes. That effect could at least double the latency, but
|
||||
the effect could be even higher because of complex network interactions.
|
||||
Second, only about two-thirds of peer nodes responded to ping requests.
|
||||
The incomplete response rate could cause sample selection bias issues.
|
||||
|
||||
Occasionally, two of the logging nodes were connected to the same
|
||||
peer node at the same time. Data from these simultaneous connections
|
||||
can be analyzed to reveal the transaction broadcast delay patterns.
|
||||
The logging nodes did not try to synchronize their system clocks.
|
||||
The following analysis used the pair of logging nodes whose system
|
||||
clocks seemed to be in sync.
|
||||
|
||||
\begin{figure}[H]
|
||||
\caption{Time difference between tx receipt, one-second cycle}
|
||||
\label{fig-one-second-period-tx-p2p-msg}
|
||||
\centering{}\includegraphics[scale=0.5]{images/one-second-period-tx-p2p-msg}
|
||||
\end{figure}
|
||||
|
||||
During the data logging period, Monero nodes drew a random variable
|
||||
from a Poisson distribution to create transaction broadcast timers
|
||||
for each of its connections. The distribution may change to exponential
|
||||
in the future.\footnote{\url{https://github.com/monero-project/monero/pull/9295}}
|
||||
The raw draw from the Poisson distribution set the rate parameter
|
||||
$\lambda$ to 20 seconds. Then, the draw is divided by 4. The final
|
||||
distribution has a mean of 5 seconds, with possible values at each
|
||||
quarter second. If a node is following the protocol, we should observe
|
||||
two data patterns when we compute the difference between the arrival
|
||||
times of a transaction between two logging nodes. First, the differences
|
||||
should usually be in quarter second intervals. Second, the difference
|
||||
should follow a Skellam distribution, which is the distribution that
|
||||
describes the difference between two Poisson-distributed independent
|
||||
random variables. These patterns will not be exact because of difference
|
||||
in network latencies.
|
||||
|
||||
Figure \ref{fig-one-second-period-tx-p2p-msg} shows a circular kernel
|
||||
density plot of the time difference between two nodes receiving the
|
||||
same transaction from the same peer node. The data in the plot was
|
||||
created by taking the remainder (modulo) of these time differences
|
||||
when divided by one second. The results are consistent with expectations.
|
||||
The vast majority of time differences are at the 0, 1/4, 1/2, and
|
||||
3/4 second mark.
|
||||
|
||||
Figure \ref{fig-skellam-histogram-tx-p2p-msg} shows a histogram of
|
||||
the empirical distribution of time differences and a theoretical Skellam
|
||||
distribution.\footnote{The Skellam distribution probability mass function has been re-scaled
|
||||
upward by a factor of 8 to align with the histogram. Each second contains
|
||||
8 histogram bins. } The histogram of the real data and the theoretical distribution are
|
||||
roughly similar except that the number of empirical observation at
|
||||
zero is almost double what is expected from the theoretical distribution.
|
||||
A zero value means that the two logging nodes received the transaction
|
||||
from the peer node at almost the same time.
|
||||
|
||||
\begin{figure}[H]
|
||||
\caption{Histogram of time difference between tx receipt}
|
||||
\label{fig-skellam-histogram-tx-p2p-msg}
|
||||
\centering{}\includegraphics[scale=0.5]{images/skellam-histogram-tx-p2p-msg}
|
||||
\end{figure}
|
||||
|
||||
\bibliographystyle{apalike-ejor}
|
||||
\bibliography{monero-black-marble-flood}
|
||||
|
|
|
|||
26
Monero-Black-Marble-Flood/pdf/tables/multiple-send-p2p.tex
Normal file
26
Monero-Black-Marble-Flood/pdf/tables/multiple-send-p2p.tex
Normal file
|
|
@ -0,0 +1,26 @@
|
|||
\begin{longtable}{Rp{2.25cm}Rp{3cm}Rp{2.25cm}}
|
||||
\caption{
|
||||
{\large Time between duplicate transaction receipts}
|
||||
} \\
|
||||
\toprule
|
||||
Number of times received & Median minutes elapsed since previous time tx received & Number of txs (rounded to 10) \\
|
||||
\midrule\addlinespace[2.5pt]
|
||||
2nd & 5.75 & 5,447,330 \\
|
||||
3rd & 11.93 & 1,386,920 \\
|
||||
4th & 21.92 & 596,310 \\
|
||||
5th & 41.96 & 90,900 \\
|
||||
6th & 85.30 & 22,180 \\
|
||||
7th & 161.26 & 16,200 \\
|
||||
8th & 2.03 & 9,710 \\
|
||||
9th & 1.97 & 8,930 \\
|
||||
10th & 1.99 & 8,930 \\
|
||||
11th & 2.02 & 8,930 \\
|
||||
12th & 4.03 & 1,090 \\
|
||||
13th & 4.03 & 1,070 \\
|
||||
14th & 4.03 & 1,070 \\
|
||||
15th & 4.03 & 1,050 \\
|
||||
16th & 4.00 & 1,050 \\
|
||||
17th & 240.03 & 60 \\
|
||||
\bottomrule
|
||||
\label{table-multiple-send-p2p}
|
||||
\end{longtable}
|
||||
21
Monero-Black-Marble-Flood/pdf/tables/tx-clumping-p2p.tex
Normal file
21
Monero-Black-Marble-Flood/pdf/tables/tx-clumping-p2p.tex
Normal file
|
|
@ -0,0 +1,21 @@
|
|||
\begin{longtable}{Rp{2.25cm}Rp{3cm}}
|
||||
\caption{
|
||||
{\large Transactions clumping in gossip messages}
|
||||
} \\
|
||||
\toprule
|
||||
Number of txs in message & Share of messages (percentage) \\
|
||||
\midrule\addlinespace[2.5pt]
|
||||
1 & 25.05 \\
|
||||
2 & 25.78 \\
|
||||
3 & 19.54 \\
|
||||
4 & 12.72 \\
|
||||
5 & 7.38 \\
|
||||
6 & 4.00 \\
|
||||
7 & 2.12 \\
|
||||
8 & 1.11 \\
|
||||
9 & 0.59 \\
|
||||
10 & 0.34 \\
|
||||
> 10 & 1.27 \\
|
||||
\bottomrule
|
||||
\label{table-tx-clumping-p2p}
|
||||
\end{longtable}
|
||||
Loading…
Reference in a new issue